Setting Up a Portable Library with ZotFile
Lee Hachadoorian on Dec 14th 2013
For the last two years, I have used a combination of calibre and Zotero to manage my research sources, mostly PDFs of journal articles. Zotero is great for reference management and automatic citation. I force my first-year seminar students to use it for their research papers, and even upper division students who have not used a reference manager before have their minds blown when they realize they no longer need to keep track of where the commas go in a citation. Enough people love Zotero that I hardly need to sing its praises. But I don’t like its obtuse, iTunes-like management of your library in a hierarchy of meaninglessly named subfolders, and I also wanted something that could sync my library to my Kindle DX.
I started using calibre, which is primarily intended as an e-reader manager, for that reason, and also for the fact that it allows easy conversion to e-reader file formats from HTML, DOC(X), and also from EPUB (which the Kindle can’t read) to MOBI (which it can). (It does offer PDF conversion as well, but I found the results to be not very good, so I read native PDFs on the Kindle.) Additionally, while calibre also does not give you control over the library folder hierarchy and file naming, it at least uses a human-readable hierarchy based on <author(s)>/<article name>/<article name>.<extension>. (Article name is duplicated in the folder hierarchy and the file name because multiple formats of the article, such as PDF and EPUB, may coexist in the folder.) This meant that when I found a journal article I wanted to read, I had to import it to calibre, import the bibliographic data to Zotero, and link from the Zotero database to the file in the calibre storage hierachy. While no single step is difficult in and of itself, doing three things instead of one always inspires a certain amount of laziness, so it meant that my libraries often got out of sync. In practice this usually meant that I had the article to read on my Kindle, but not in Zotero. Additionally, time I spent updating metadata in calibre had limited payoff because I couldn’t use calibre for citation.
Since nothing sidetracks writing a paper like finding out your sources aren’t in order, I’ve decided it’s more important to prioritize the reference manager, and want to use Zotero to manage my library. Fortunately, Zotero has some ways to add these desired features, including the ZotFile plugin for library management (which has been around for awhile, but since I was managing my library in calibre, I haven’t used ZotFile until now). ZotFile lets you specify an alternate location to store your attached files, and gives you control over the folder hierarchy and file naming (similar to Mendeley, or to many music players; note, calibre also gives you this kind of control, but you have to export your library to an alternate location, duplicating all your files–it doesn’t allow you to mess with its internal library structure). The instructions for doing this on the developer’s web page were a little unclear to me, so I went looking for help in the Zotero forums, and found a thread from today started by a new user who was looking for guidance in how to do the same thing. In this post, I’ll explain how to accomplish this.
First, you have to understand that Zotero draws a distinction between saving a file internally (which it calls “stored” files), and saving a link to a file anywhere on your hard drive, though both stored and linked files are called “attachments”. Part of the reason why its internal naming is so obtuse is probably because they don’t want you messing with it and moving files around. If you want a pretty, human-readable hierarchy, you need to tell ZotFile how to construct that hierarchy. Since linked files can be anywhere on your hard drive, by default Zotero saves their location using absolute paths. If you want to share your files across computers, you need to instead tell Zotero to interpret all file paths relative to your human-readable hierarchy.
- Go to Zotero Preferences (using File→Preferences, or using the gear icon). Click the Advanced icon at the top, then the Files and Folders tab.
- Under Linked Attachment Base Directory, hit the Choose button and use the file browser to pick the folder where you want your library to be organized:
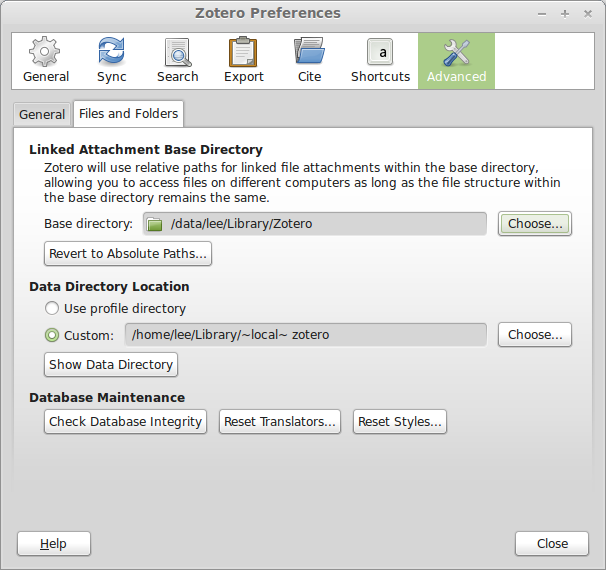
NOTE: You do not have to change the Data Directory Location. This is the location of your Zotero database, and also where PDFs are stored internally, but the whole point of what we are doing is to not store the files internally. - Now go to ZotFile (not Zotero) Preferences, by clicking the gear icon, and go to General Settings.
- Under Location of Files, click Custom Location, and set it to the same folder you just set as the Linked Attachment Base Directory.
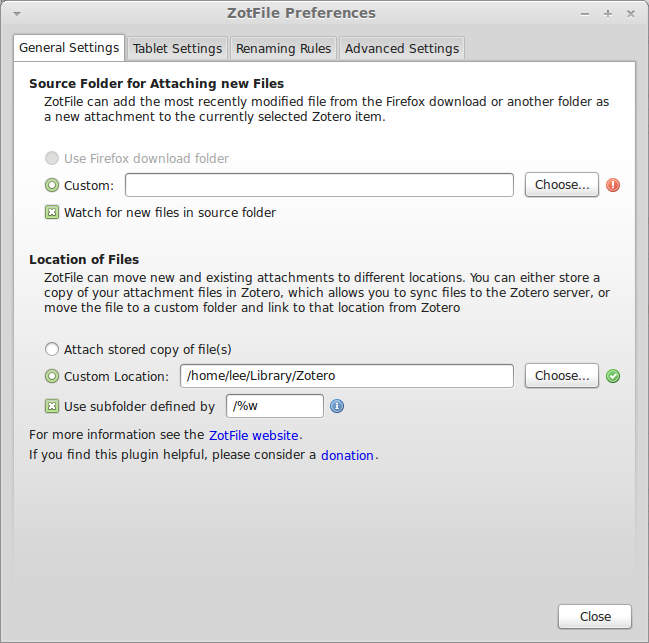
- Check “Use subfolder defined by”. The default, `/%w/%y`, will organize your files into directories by journal/publisher (uses the publisher name if there is no journal name, e.g. for books) and year. Since I want to be able to navigate this directory sensibly, and I can’t always remember the year a paper was written, I dropped year from the definition. The codes used here and in the next stop are listed in detail at the ZotFile website.
- Click the Renaming Rules tab. Leave “Use Zotero to rename” unchecked. The default naming rule is `{%a_}{%y_}{%t}` which would generate something like “Smith_2013_This is my title.pdf”. I don’t like underscores in my filenames, so I set my renaming rule to `{%a }{%y – }{%t}`, which would produce “Smith 2013 – This is my title.pdf”, and changed the delimiter between multiple authors to an ampersand surrounded by spaces. Others might prefer a comma. If the filesystem can handle long names, I don’t see why I shouldn’t take advantage of that, so I unchecked both “Truncate title after . or : or ?” and “Maximum length of title”. I left the maximum number of authors at 2, and the use of “et al” for more than two authors.
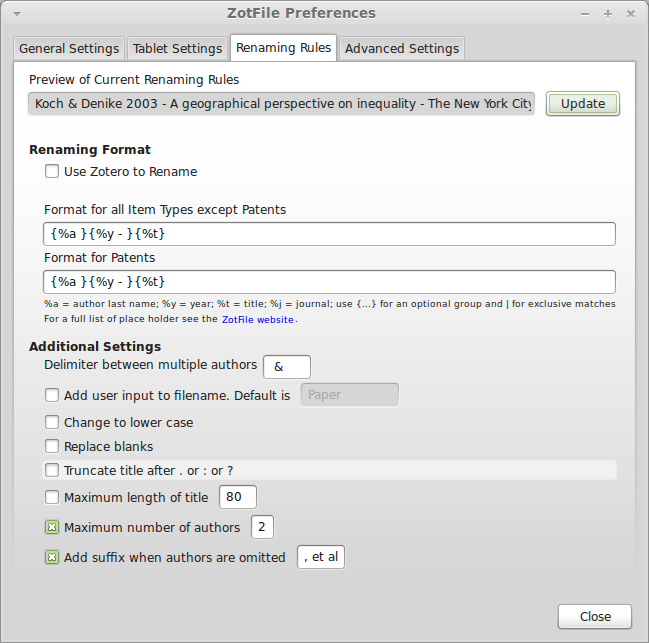
- At this point you can select an item in the main Zotero window and click the Update button at the top of the dialog to see how the file will be renamed. If you are satisfied with it, hit the Close button.
- Now we want to actually move our attached files to this new hierarchy. I began by sorting my library on the attachments column (just click on the paper clip at the top of the column). Then Shift+Click to select all the items with attachments. Right-click on the selected files and choose Manage Attachments→Rename Attachments. ZotFile will now move the files to the Location of Files specified in the preferences. It will do this for both attachments, like the files in my calibre library, and Zotero’s own internally stored files, which will become attachments in the new location, and no longer be stored internally. But this will not move web page snapshots, which stay internal.
Do keep in mind that ZotFile does not copy the files, it moves them. Since my attached files were in my calibre library, and I’m not giving up on calibre just yet, I didn’t really want them deleted from their original location. I backed up my calibre library so that I could allow ZotFile to move the files to the new location, then restored my calibre library from the backup. But I kept the backup for the next step. Since I had a lot of sources in the Zotero database (hundreds) that were not linked to the PDFs in calibre, I could link to the PDFs in this backup, then move them with Manage Attachments→Rename Attachments without affecting my calibre library.
Storing the files this way has two advantages over storing them internally. First, since they are in a human-readable hierarchy, I can pretty quickly find a file through the file browser of another application—for example, if I am writing an email to a colleague and want to attach an article— without having to switch to Zotero first. Second, although Zotero supports WebDAV for library syncing, and Zotero’s own storage is not that expensive, using ZotFile to organize your attachments this way allows you to use any cloud service to keep your library synced across computers, such as Dropbox (mentioned by the new user who started the forum thread linked above) or SpiderOak (my preferred backup/share/sync service).
I ran into a little bit of an issue in that I use Zotero Standalone. This requires me to also have Zotero for Firefox installed so that I can import sources while web browsing. But the preferences did not propagate between them (for either Zotero or ZotFile), so I had to independently set the Linked Attachment Base Directory, Location of Files, and Renaming Rules in both Standalone and the Firefox plugin.
While I’m pretty happy with the result, this all leaves calibre and Kindle syncing out of the equation. Using external PDF reader applications, ZotFile can also manage syncing PDFs, including annotations, between your Zotero library and iPad or Android tablets. Maybe there’s a way to get this to work with calibre to keep my library synced with my Kindle? That will be the next thing to figure out…
Thanks to Zotero forum users bwiernik and adamsmith.
Filed in Productivity | 3 responses so far
Maps of NYPD Stops, 2011
Lee Hachadoorian on Dec 2nd 2013

The Bronx is heavily Black and Latino, and shows a high number of NYPD stops over much of the borough.
There have been a lot of ups and downs in the battle over the NYPD Stop and Frisk program. Over the Summer, a federal judge ruled the program unconstitutional as practiced, and appointed a federal monitor to oversee reforms. Then, a month ago, a federal appeals panel removed Judge Scheindlin from the case, and put a stay on her orders. Bill de Blasio was elected mayor promising to drop the City’s appeal, but lame duck Mayor Bloomberg tried to push the appeal to a full overturning of Judge Scheindlin’s ruling before leaving office. Now the full Second Circuit has put on hold any further action while the litigants negotiate—clearly taking the ball from Bloomberg and passing it to the mayor-elect.
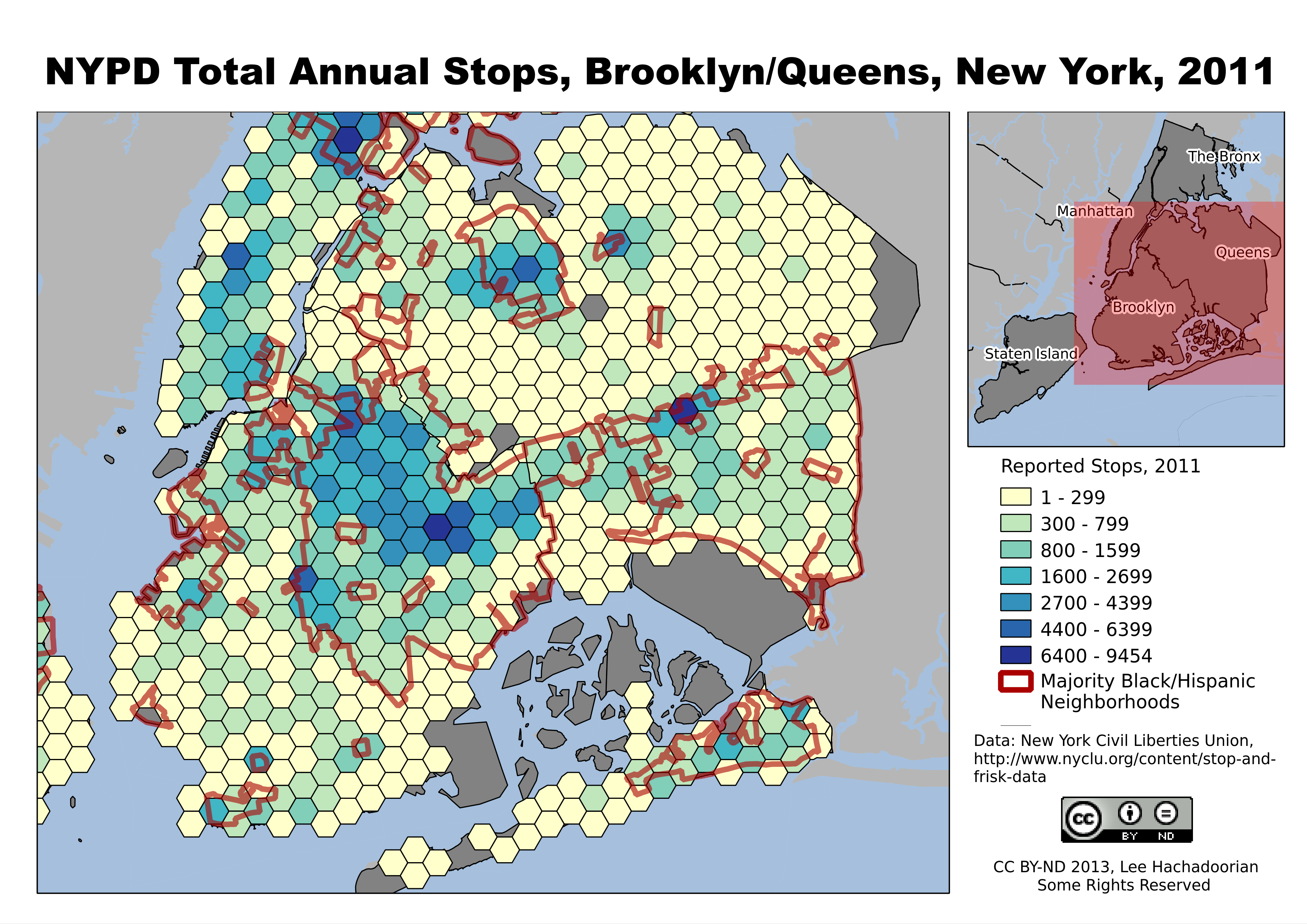
Stops are concentrated in predominantly Black and Latino neighborhoods like Bedford-Stuyvesant and East New York in Brooklyn, and East Elmhurst and Jamaica in Queens.
Much of the focus in the case has been on whether the Stop and Frisk program was implemented in a racially biased manner, with considerable concern over the targeting of young Blacks and Latinos. The maps I’ve created, based on the 2011 statistics, do show many more stops taking place in predominantly Black and Latino neighborhoods. The maps do not show the race of the people being stopped, an important consideration in the trial, as plaintiffs presented evidence that the “hit rate”—stops that actually led to the discovery of a crime—was much lower for Black and Latinos than for Whites, indicating that the police were using a different, and looser, standard for what they regarded as suspicious behavior by Blacks and Latinos.
The main exception to the correlation between neighborhood demographics and volume of police stops is in Manhattan. We do see a concentration of stops in the Black and Latino neighborhoods of Harlem and Washington Heights, but we also see generally higher stops in Manhattan than in the outer boroughs. Doubtless this is due to Manhattan’s generally higher nonresidential population (commuters, shoppers, etc.), as well as the generally higher pedestrian counts in Lower Manhattan and Midtown.
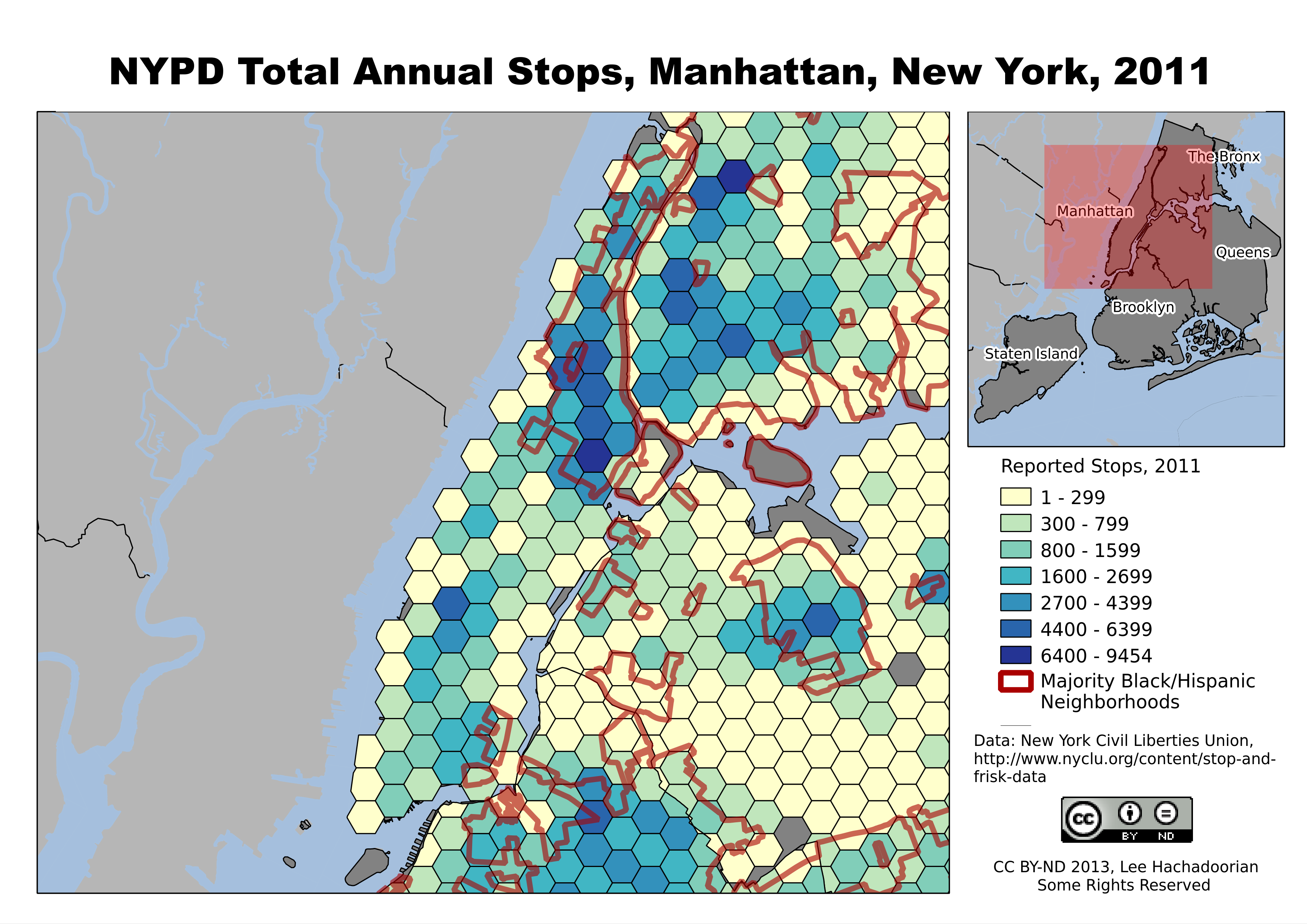
Manhattan, with its high daily influx of nonresidents for employment, shopping, and commercial activities, has high numbers of NYPD stops throughout the borough.
While the differences in “hit rate” helped Judge Scheindlin conclude that this policy led to “indirect racial profiling”, the ridiculously low yield—less than 12% of stops led to a summons or arrest in 2011 (about equally split)—suggests that the police are extremely poor judges of suspicious behavior. But what do you expect of a policy that allows the police to stop someone for “inappropriate attire for season” (about 7.5% of stops in 2011)?
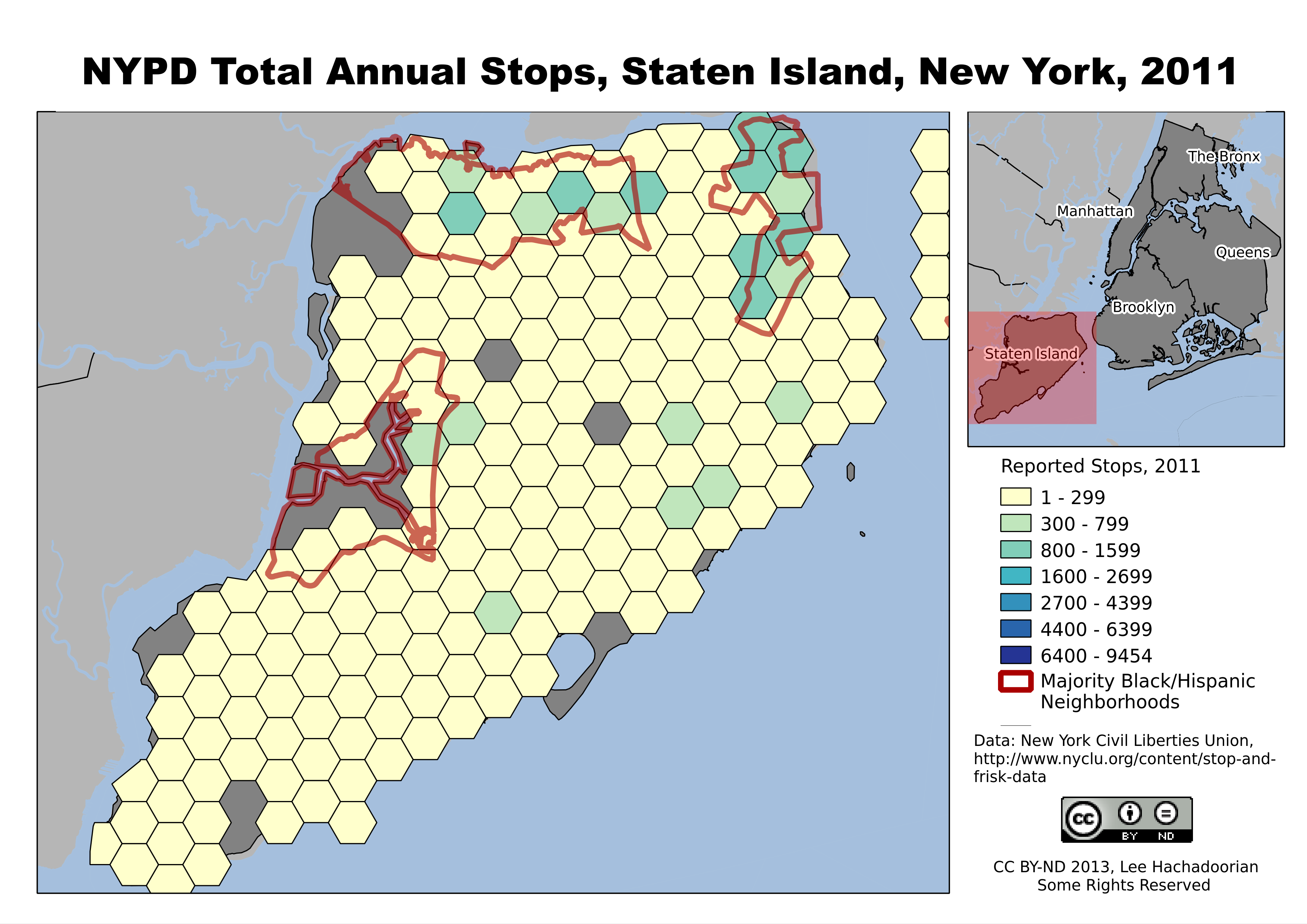
Staten Island’s population is more White, and subject to fewer police stops.
Filed in GIS,Governance | One response so far
Recent Victories for Open Geospatial Data
Lee Hachadoorian on Aug 28th 2013
The tagline of this blog is “Urban Economic Geography and Open Everything”. Free City supports free and open source software, open access publishing, and open data. Many governments are making much of their data publicly available, including New York City’s own open data portal. But geospatial data has sometimes been handled differently, sometimes because of privacy concerns, often because of security concerns. For example, the New York State GIS Clearinghouse allows direct downloading of orthoimagery (aerial photography) for much of the state, but for sensitive areas, including all of New York City, there is are some hoops to jump through.
Doubtless some of the evocation of privacy and security concerns is disingenuous, as much of the protected data is nonetheless commercially available. But in some cases it is the government itself which is licensing the data, raising the question of why they are only willing to give it to people who pay for it. In two recent cases having to do with property records, local governments chose or were forced to make their geographic data freely available. New York City’s Department of City Planning recently chose to make its MapPLUTO database available for download, whereas previously they had charged $300 per borough for this collection of building and tax records joined to parcel footprints. On the other side of the country, Orange County, California was forced by a court decision to open up their parcel database, which they had previously been licensing for $375,000!
In the Orange County case, the county was forced to release the data under the existing Public Records Act. Why wasn’t it already available? Because it was GIS data! The county claimed that the data was exempt because it was “software”. The California Supreme Court sensibly rejected that claim. After all, if the same information had been requested in hard copy, the county would have been legally required to provide it (and would have realized as much). I would go even further and ask, why is there an exemption for software? As a free software advocate, I would argue that the same reasons that apply to public records also apply to publicly developed software, including that it is paid for with tax dollars, and that there is a public benefit to its wide availability. There could still, as is the case with public records, be security exceptions for certain kinds of software.
The lawsuit which led to this case was filed by the Sierra Club, which had requested the parcel data for use in conservation planning. As a nonprofit, they could not afford the $375,000 licensing fee. Now that the court has ruled that the data are not exempt from the existing law, the Sierra Club will be able to obtain the data “for the cost of producing the physical copy”, presumably the cost of some DVDs, or free if provided electronically. In the New York case, the fees weren’t nearly so egregious, but nonetheless, I knew of small nonprofits, and—until the Grad Center licensed the data—CUNY grad students who could not afford to pay them.
The size of the fees—a lot for a grad student, not a lot for a government the size of New York City’s—really call into question why they existed in the first place. At $375,000 a pop, Orange County claimed that the fees helped support the GIS services that made the data available in the first place. But NYC’s Department of City Planning was only collecting $50 to $80 thousand a year from their licensing scheme, which is pretty small potatoes. Furthermore, at least one nonprofit obtained the data for free through a NYS Freedom of Information Law Request! So DCP, unlike Orange County, did not even attempt to argue that the data were exempt from its state’s public records law. But they did require the nonprofit to sign the standard license agreement, which restricted redistribution of the data. This does seem to suggest that, rather than pecuniary interest, DCP was more interested in asserting control over the data for some reason or another, and that there was something about this data in particular that it was concerned about, since it provided virtually all of its other data for free via public download.
Thanks are due to Steve Romalewski, my friend and former boss at Center for Urban Research. Steve has advocated for the freeing of this data set for some time, and in announcing the new DCP policy on his blog, he thanks several others in academia, journalism, and the nonprofit world for their contribution to this wonderful result.
Filed in GIS | Comments Off on Recent Victories for Open Geospatial Data
QGIS Fast SQL Layer
Lee Hachadoorian on May 7th 2012
PostGIS and SpatiaLite offer a large number of spatial query operations, including buffers, intersections, and spatial joins. It’s really useful, especially when you’re still experimenting, to visualize your results without having to create a new spatial table, spatial view, or exporting to a shapefile or other GIS data format. Fortunately, there are several ways to do this, including at least three plugins for Quantum GIS: Fast SQL Layer, PostGIS Query Editor, and RT SQL Layer. In this blog post I will walk you through using Fast SQL Layer. Continue Reading »
Filed in Computing,GIS | One response so far
Lenovo IdeaPad Y560p Keyboard Possessed by Demon
Lee Hachadoorian on Apr 19th 2012
Normally I don’t write about hardware on this blog (or pretty much anywhere), but I’m making an exception in this case to shout out a thank you to Theje for a YouTube video showing how to fix a weird keyboard problem on my IdeaPad Y560p. Certain keys quite suddenly started doing strange things: The H key would act like an up arrow, so while you were typing, your words would suddenly start appearing in the middle of the last line. Continue Reading »
Filed in Computing,General | Comments Off on Lenovo IdeaPad Y560p Keyboard Possessed by Demon
New York State Celebrates the 200th Anniversary of the Gerrymander
Lee Hachadoorian on Mar 30th 2012
Colleagues at Center for Urban Research have posted a fun interactive map for visualizing the various New York State redistricting proposals. New York, like all states, is redrawing state and federal legislative districts based on the 2010 Census. So far, it’s not going so good. The proposals released by the legislature have been widely criticized for not preserving “communities of interest”, a common redistricting desideratum. The legislature was unable to agree on federal districts, and left that up to a federal court. State legislative districts were signed into law by Gov. Cuomo, in exchange for a legislative pledge to create a bipartisan redistricting panel for the next go round (i.e., 2020). But the redistricting reform that is shaping up has been criticized by a former New Yorker and current member of the California Citizens Redistricting Commission for, among other things, leaving final adoption in the hands of the legislature. Continue Reading »
Filed in GIS,Governance | Comments Off on New York State Celebrates the 200th Anniversary of the Gerrymander
Spatialite GUI
Lee Hachadoorian on Jan 31st 2012
Why SpatiaLite?
{kind=link}
I spent this weekend getting the SpatiaLite GUI installed, with help from SpatiaLite Users Google Group. SpatiaLite is an open source source geodatabase built on top of SQLite, itself an open source database. As a lightweight, “server-less” database, SQLite is frequently used as an embedded database by other applications, including Firefox, Google Chrome, Skype, iTunes, Clementine (my preferred FOSS music player), and Dropbox (on the client side). Continue Reading »
Using the Kindle DX as a PDF Reader
Lee Hachadoorian on Dec 14th 2011
I was never particularly interested in reading novels on the Kindle, but as an academic I have reams of journal articles—most in PDF format—that I need to read and consult for my research. Many of you will know what I mean when I say that I can’t stand reading on a computer monitor. But printing the articles is problematic, too. There’s the obvious environmental concern, which I partially mitigate by printing everything 4-up double-sided (usually prompting onlookers to ask “Can you read that?!!”), but even then there’s the problem of actually having the articles with you when you find yourself with downtime on the subway, at the doctor’s office, etc. So when my parents asked me what I wanted as a graduation gift…
Which Kindle?
When I got it last May, Amazon had not yet released the Kindle Touch or the Kindle Fire, so my choice was basically between the 6” screen (now renamed Kindle Keyboard) with WiFi (and optionally with 3G wireless) and the 9.7” Kindle DX with 3G wireless only. Obviously, as with laptops, there’s a portability/usability tradeoff. But not knowing how well PDFs would convert to the Amazon e-reader format (read further for notes on PDF conversion), I picked the larger-screen Kindle DX for full-page PDF viewing. Continue Reading »
Filed in Productivity | 2 responses so far
Downgrading a Package in Ubuntu
Lee Hachadoorian on Oct 28th 2011
Never satisfied with something that is already working (Firefox), a few months ago I decided to check out Chromium, the open source version of Google’s Chrome web browser. My impression is that it is very snappy at page loads. In looking into which browser would be better on an old, hardware-challenged computer (a Sony VAIO with a 1.2 GHz Pentium M and 512 MB RAM), I found that Tom’s Hardware reports that while Chrome has a heavier memory footprint, it also has faster page loads. On low-end systems that makes it kind of a toss-up—will the increased memory demands translate into a faster feel in your browsing?—but on my 6 GB RAM Dell desktop and my 8 GB RAM Lenovo laptop, the OS can easily afford to throw a couple of GB to Chromium in exchange for a faster browsing experience. Continue Reading »
Filed in Computing,General | One response so far
Mindmapping for…well, everything!
Lee Hachadoorian on Jan 15th 2011
It was probably a year-and-a-half ago, while participating in a Summer-long proposal writing workshop with other members of the New York Graduate Urban Research Network, that a fellow graduate student recommended the use of mind maps to help organize some of my ideas. (This after I sketched something that looked like a Venn diagram of overlapping literatures related to my research.) I checked out some open source mindmapping software packages at the time, but it was only this last Summer that I started using one in earnest. In this post I’ll describe some of the things I use mind maps for. Continue Reading »
Filed in Computing,Productivity | 2 responses so far